
myql数据库优化与扩展
后端
架构
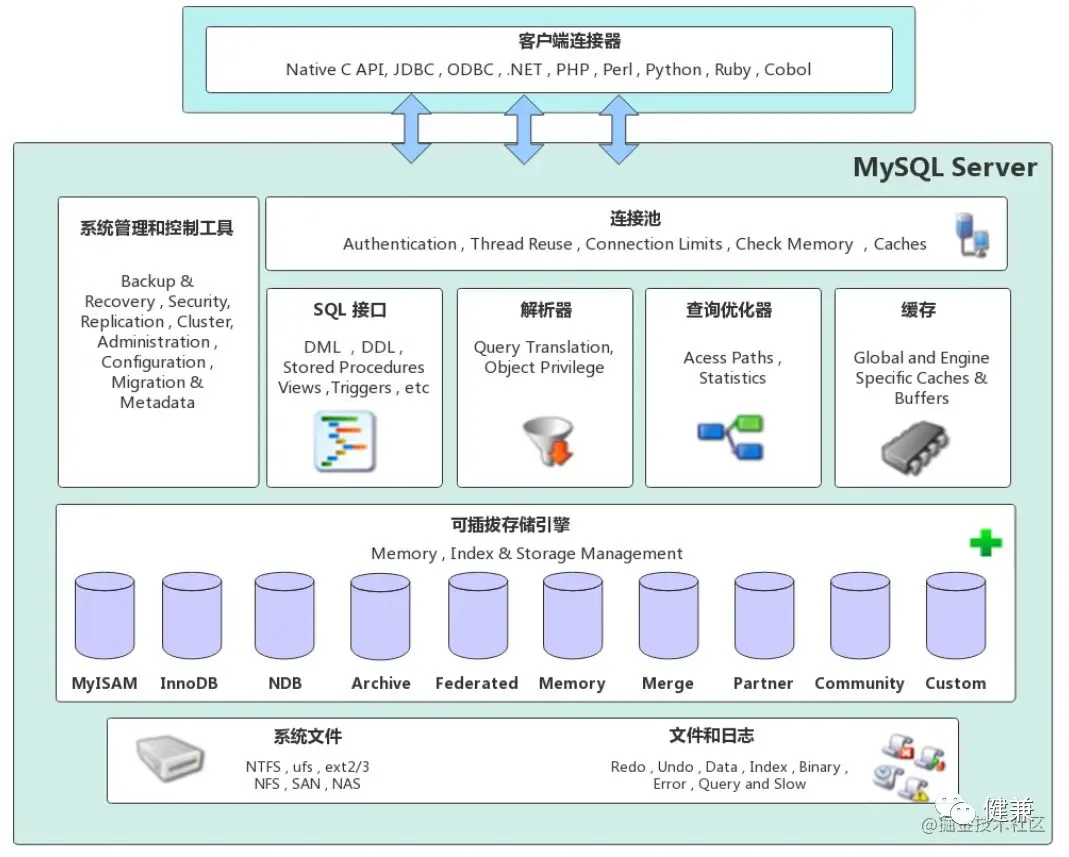
每一个连接,在单独的线程中执行,进行验证后,先判断如果在查询缓存中,直接返回结果,否则通过解析器解析优化,然后发送存储引擎查询数据返回。
性能分析与优化
读锁共享,写锁互斥;
表锁,开销小,并发低;
行锁,开销大,并发高;
死锁,互相等待对方占有的资源
事务特性,原子性、一致性、隔离性、持久性
隔离级别,读未提交(脏读)、读已提交(不可重复读)、可重复读(幻读),串行化
多版本控制协议(MVCC),系统中记录最新版本号,开启新事务会递增系统新版本号并作为此事务的版本号,事务中修改了数据,就在数据隐藏列记录事务版本号,查询时只记录小于等于此事务版本号的数据,实现了读不用加锁
慢日志
配置
1、 慢日志
#查看是否开启show variables like '%slow_query_log%';
#开启set global slow_query_log = 1;
#时间阈值show variables like '%long_query_time%'
#设置set global long_query_time = 1;
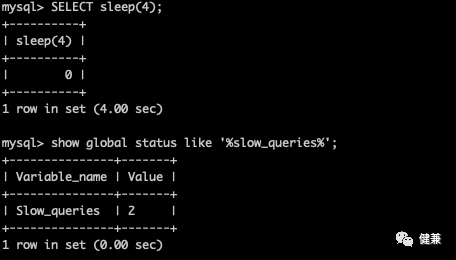
#重新打开链接,测试SELECT sleep(4);
#查看慢日志条数show global status like '%slow_queries%';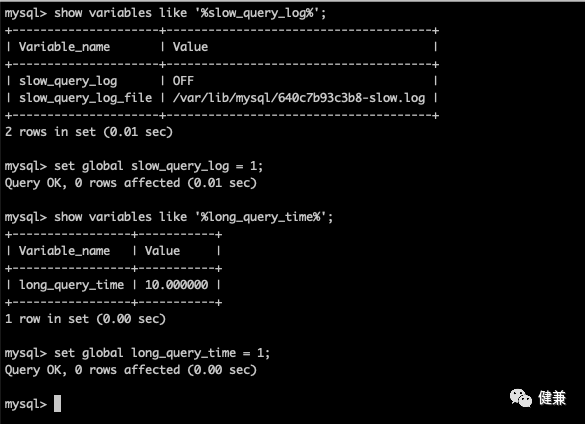
永久生效,vim /etc/mysql/my.cnf
slow_query_log =1
slow_query_log_file=/tmp/mysql_slow.log慢日志分析
mysqldumpslow [option] logfile
-s ORDER 排序方式
c: 访问计数 l: 锁定时间 r: 返回记录 t: 查询时间 al:平均锁定时间 ar:平均返回记录数 at:平均查询时间
-r 倒序排 -t NUM 只返回前几条 -g PATTERN 正则表达式
用 show profile 进行 sql 分析
show profile 用于查询 sql 执行的资源消耗,默认关闭,只记录最近 15 条
配置
#查询是否开启show variables like '%profiling%';
#开启set profiling = on;
#查看记录列表show profiles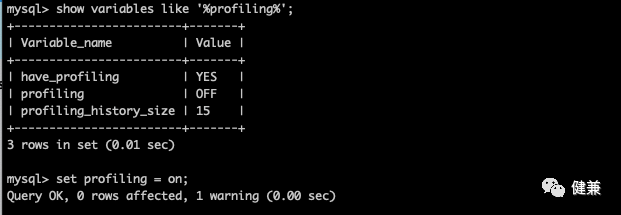
使用
show profile cpu, block io for query 5;Show profile后面的一些参数:
All:显示所有的开销信息
Block io:显示块IO相关开销
Context switches: 上下文切换相关开销
Cpu:显示cpu相关开销
Memory:显示内存相关开销
Source:显示和source_function,source_file,source_line相关的开销信息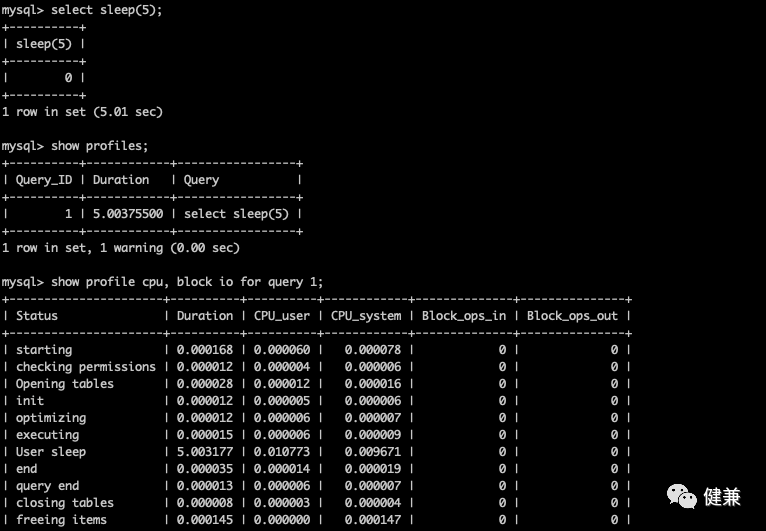
explain 执行计划
官方解释: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
- id 查询序列号,倒序执行,从上至下
- select_type 查询类型
- simple 简单查询,不包含子查询和 union
- primary 包含子查询的,最外层查询
- subquery select 或 where 里面包含子查询
- derived 在 from 列表中包含的子查询
- union 并集的第二个 select 查询
- table 指定数据来源
- partitions 匹配的分区
- type 表的连接类型,性能由高到低排列
- system 表只有一行记录,相当于系统表
- const 通过索引查找,只匹配一行
- eq_ref 索引扫描,表记录一对一关联
- ref 索引扫描,表关联
- range 索引范围查询
- index 只遍历索引树
- ALL 全表扫描
- possible_keys 使用的索引
- key 实际使用的索引
- key_len 索引中使用的字节数
- ref 显示该表的索引字段,关联了哪张表
- rows 扫描的行数
- filtered 结果返回的行数占读取的行数
- extra 额外信息
- using filesort 文件排序
- using temporary 使用临时表
- using index 使用了覆盖索引
- using where 使用了 where 子句
- using join buffer 使用连接缓冲
使用合适的数据类型
整数类型
-
使用占用空间更小的类型性能会更好
-
有符号和无符号占用空间相同,表示范围不同,性能相同
-
为整数指定宽度没有意义
实数类型
-
float 和 double 基于操作系统的浮点数近似计算
-
Decimal 是 mysql 实现的小数精确计算,需要更多的开销,比 float 和 double 性能差
-
大量财务数据,精确到最小计量单位,采用 bigint 存储
字符串类型
- Varchar 存储变长字符串
- char 存储定长字符串,存储时会剔除末尾空格
- BLOB 存储二进制;text 存储变长大字符串有字符集
日期和时间类型
- Datetime 精度秒,从 1001 年到 9999 年
- timestamp 精度秒,记录 19700101 以来的秒数,最大到 2028 年,效率比 datetime 高
索引
最左前缀匹配,不能跳过索引列
索引列参与计算,无法走索引
尽量选择区分度高的列建立索引
扩展
主从复制
读多写少,访问性能低时采用,读写分离,主从复制
-
配置
-
准备多台 MySQL 服务器
-
在每台服务器上创建复制账号,并赋予权限
Terminal window create user 'sla'@'%' identified with 'mysql_native_password' by '123456';grant replication slave on *.* to 'sla'@'%'; -
在选定的主库上,配置二进制日志和唯一的服务器 ID,通过
show master status命令检查配置server-id = 1log_bin = /var/log/mysql/mysql-bin.log# binlog_expire_logs_seconds = 2592000max_binlog_size = 100M# binlog_do_db = include_database_namebinlog_ignore_db = mysqlbinlog_ignore_db = syslog-slave-updates = 1
-
在备库上,配置二进制日志和唯一的服务器 ID,运行
change master to,通过show slave status检查备库状态server-id = 2log_bin = /var/log/mysql/mysql-bin.log# binlog_expire_logs_seconds = 2592000max_binlog_size = 100M# binlog_do_db = include_database_namebinlog_ignore_db = mysqlbinlog_ignore_db = syslog-slave-updates = 1Terminal window change master to master_host='172.17.0.2',master_user='sla',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=0;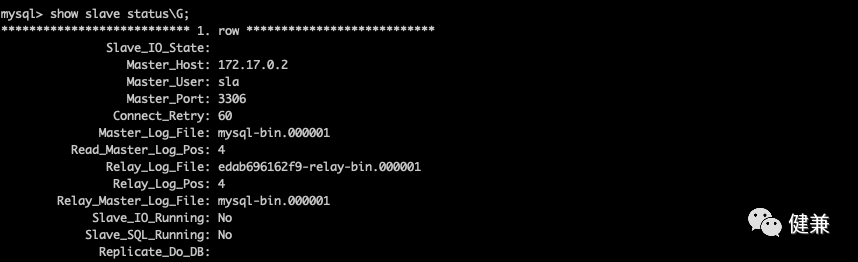
-
在备库上,执行
start slave开始复制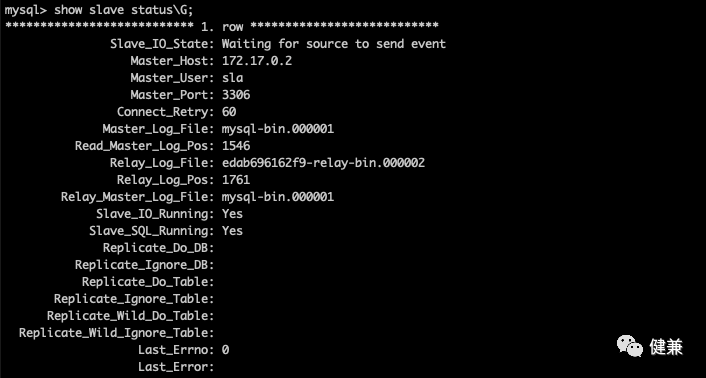
-
-
复制模式
- 基于语句模式,在从库上执行主库上的 SQL 语句
- 基于行模式,记录修改后的数据
- 混合模式
读写分离
分表
-
垂直分表
表中的字段太多,访问频率不同,将不经常访问的字段分离出来作为扩展表
-
水平分表
某个表数据量太大,按照主键或时间 range、hash 分到相同结构的多张表
分库
-
垂直分库
按功能,将不同功能相关的表放到不同的库里
-
水平分库
将表中数据分离到不同的库,每个库里表结构相同,数据不同
sharding-jdbc 框架分库分表配置
官网地址:https://shardingsphere.apache.org/
依赖配置
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <version>${spring-boot.version}</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> <version>${spring-boot.version}</version> </dependency> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.1.1</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.22</version> </dependency> <!--日志--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> <version>${spring-boot.version}</version> </dependency>
<!--测试--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <version>${spring-boot.version}</version> <exclusions> <exclusion> <artifactId>junit</artifactId> <groupId>junit</groupId> </exclusion> </exclusions> </dependency>
<dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency>初始化表结构
create database sample_1;
create table sample_1.torder_1( id bigint not null auto_increment primary key , user_id bigint not null , create_time datetime default current_timestamp()) comment '订单';
create table sample_1.torder_2( id bigint not null auto_increment primary key , user_id bigint not null , create_time datetime default current_timestamp()) comment '订单';
create database sample_2;
create table sample_2.torder_1( id bigint not null auto_increment primary key , user_id bigint not null , create_time datetime default current_timestamp()) comment '订单';
create table sample_2.torder_2( id bigint not null auto_increment primary key , user_id bigint not null , create_time datetime default current_timestamp()) comment '订单';项目配置application-share.properties
logging.config=classpath:logback/logback.xml
# 一个实体类对应两张表,覆盖spring.main.allow-bean-definition-overriding=true
# 配置真实数据源spring.shardingsphere.datasource.names=sample1,sample2
# 配置第 1 个数据源spring.shardingsphere.datasource.sample1.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.sample1.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.sample1.jdbc-url=jdbc:mysql://localhost:3306/sample_1spring.shardingsphere.datasource.sample1.username=rootspring.shardingsphere.datasource.sample1.password=root
# 配置第 2 个数据源spring.shardingsphere.datasource.sample2.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.sample2.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.sample2.jdbc-url=jdbc:mysql://localhost:3306/sample_2spring.shardingsphere.datasource.sample2.username=rootspring.shardingsphere.datasource.sample2.password=root
# 配置 torder 表规则spring.shardingsphere.sharding.tables.torder.actual-data-nodes=sample$->{1..2}.torder_$->{1..2}
# 主键生成策略spring.shardingsphere.sharding.tables.torder.key-generator.column=idspring.shardingsphere.sharding.tables.torder.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.torder.database-strategy.inline.sharding-column= user_idspring.shardingsphere.sharding.tables.torder.database-strategy.inline.algorithm-expression= sample${user_id % 2+1}
# 配置分表策略spring.shardingsphere.sharding.tables.torder.table-strategy.inline.sharding-column=idspring.shardingsphere.sharding.tables.torder.table-strategy.inline.algorithm-expression=torder_${id % 2+1}
# 日志打印sqlspring.shardingsphere.props.sql.show=true测试代码
@RunWith(SpringRunner.class)@SpringBootTest(classes = MainApp.class)public class MainAppTest {
@Autowired TorderMapper torderMapper;
@Autowired NamedParameterJdbcTemplate jdbcTemplate;
@Test public void test() throws Exception{ System.out.println("sssss");
for (int i=2;i<10;i++){ Torder torder = new Torder(); torder.setUserId(new Long(i)); torder.setCreateTime(new Date()); torderMapper.insert(torder); }
}
@Test public void testss() throws Exception{ System.out.println("sssss");
String s = "insert into torder(user_id, create_time) values (:userId,:createTime)"; for (int i=2;i<10;i++){ MapSqlParameterSource mapSqlParameterSource = new MapSqlParameterSource(); mapSqlParameterSource.addValue("userId",new Long(i)); mapSqlParameterSource.addValue("createTime",new Date()); jdbcTemplate.update(s,mapSqlParameterSource); }
}
}效果
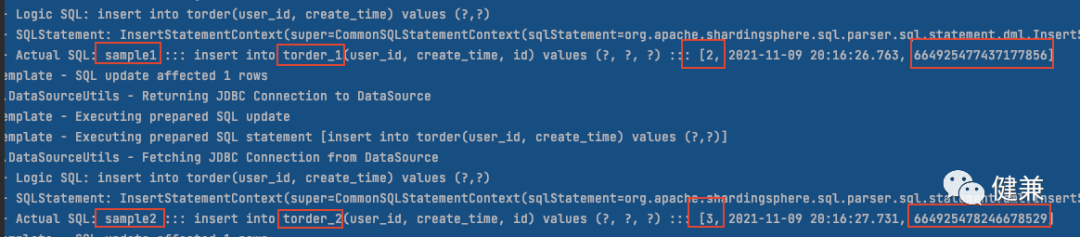
sharding-jdbc 框架读写分离配置
项目配置application-rw.properties
# 一个实体类对应两张表,覆盖spring.main.allow-bean-definition-overriding=true
# 配置真实数据源spring.shardingsphere.datasource.names=sample1,sample2,sample1s1,sample2s1
# 配置第 1 个数据源spring.shardingsphere.datasource.sample1.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.sample1.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.sample1.jdbc-url=jdbc:mysql://localhost:3306/sample_1spring.shardingsphere.datasource.sample1.username=rootspring.shardingsphere.datasource.sample1.password=root
# 配置第 1 个slave数据源spring.shardingsphere.datasource.sample1s1.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.sample1s1.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.sample1s1.jdbc-url=jdbc:mysql://localhost:13306/sample_1spring.shardingsphere.datasource.sample1s1.username=rootspring.shardingsphere.datasource.sample1s1.password=root
# 配置第 2 个数据源spring.shardingsphere.datasource.sample2.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.sample2.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.sample2.jdbc-url=jdbc:mysql://localhost:3306/sample_2spring.shardingsphere.datasource.sample2.username=rootspring.shardingsphere.datasource.sample2.password=root
# 配置第 2 个slave数据源spring.shardingsphere.datasource.sample2s1.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.sample2s1.driver-class-name=com.mysql.cj.jdbc.Driverspring.shardingsphere.datasource.sample2s1.jdbc-url=jdbc:mysql://localhost:13306/sample_2spring.shardingsphere.datasource.sample2s1.username=rootspring.shardingsphere.datasource.sample2s1.password=root
## 主从读写分离spring.shardingsphere.sharding.master-slave-rules.ds1.master-data-source-name=sample1spring.shardingsphere.sharding.master-slave-rules.ds1.slave-data-source-names[0]=sample1s1spring.shardingsphere.sharding.master-slave-rules.ds1.load-balance-algorithm-type=ROUND_ROBIN
spring.shardingsphere.sharding.master-slave-rules.ds2.master-data-source-name=sample2spring.shardingsphere.sharding.master-slave-rules.ds2.slave-data-source-names[0]=sample2s1spring.shardingsphere.sharding.master-slave-rules.ds2.load-balance-algorithm-type=ROUND_ROBIN
# 配置 torder 表规则spring.shardingsphere.sharding.tables.torder.actual-data-nodes=ds$->{1..2}.torder_$->{1..2}
# 主键生成策略spring.shardingsphere.sharding.tables.torder.key-generator.column=idspring.shardingsphere.sharding.tables.torder.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.torder.database-strategy.inline.sharding-column= user_idspring.shardingsphere.sharding.tables.torder.database-strategy.inline.algorithm-expression= ds$->{user_id % 2+1}
# 配置分表策略spring.shardingsphere.sharding.tables.torder.table-strategy.inline.sharding-column=idspring.shardingsphere.sharding.tables.torder.table-strategy.inline.algorithm-expression=torder_$->{id % 2+1}
# 日志打印sqlspring.shardingsphere.props.sql.show=true测试代码
@RunWith(SpringRunner.class)@SpringBootTest(classes = MainApp.class)public class MainAppTest {
@Autowired NamedParameterJdbcTemplate jdbcTemplate;
@Test public void testss() throws Exception{ System.out.println("sssss");
String s = "insert into torder(user_id, create_time) values (:userId,:createTime)"; for (int i=33;i<36;i++){ MapSqlParameterSource mapSqlParameterSource = new MapSqlParameterSource(); mapSqlParameterSource.addValue("userId",new Long(i)); mapSqlParameterSource.addValue("createTime",new Date()); jdbcTemplate.update(s,mapSqlParameterSource); }
String s2 = "select * from torder where user_id = :userId "; for (int i=33;i<36;i++){ MapSqlParameterSource mapSqlParameterSource = new MapSqlParameterSource(); mapSqlParameterSource.addValue("userId",new Long(i)); jdbcTemplate.queryForList(s2,mapSqlParameterSource); } }
}结果
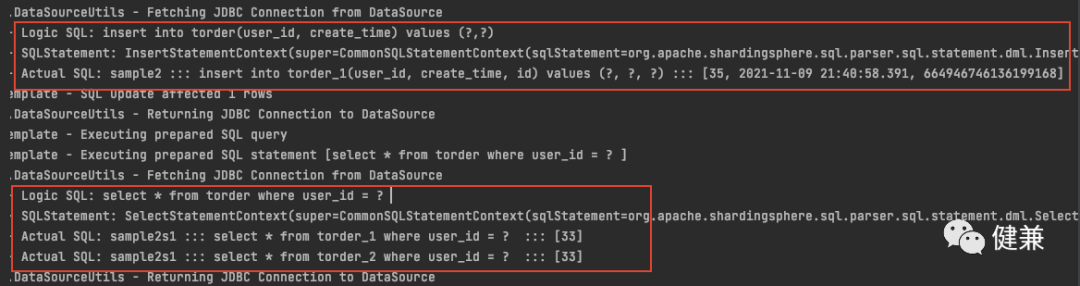
备份与恢复
逻辑备份
mysqldump -uroot -proot --all-databases >/tmp/all.sqlmysqldump -uroot -proot --databases db1 db2 >/tmp/user.sqlmysqldump -uroot -proot --databases db1 --tables a1 a2 >/tmp/db1.sql参考https://www.cnblogs.com/chenmh/p/5300370.html
物理备份
安装percona-xtrabackup-80
wget https://repo.percona.com/apt/percona-release_latest.$(lsb_release -sc)_all.deb
dpkg -i percona-release_latest.$(lsb_release -sc)_all.deb
percona-release enable-only tools release
apt-get update
apt-get install percona-xtrabackup-80
apt-get install qpress执行备份恢复
#备份
xtrabackup --backup --target-dir=/data/backups/full/ -utest -pA@test.com
#回滚没有提交的日志,准备恢复
xtrabackup --prepare --target-dir=/data/backups/full/
#数据恢复
xtrabackup --copy-back --target-dir=/data/backups/full/